The Science of GPT
- Madhuri Pagale
- Mar 20, 2025
- 4 min read

Updated: Mar 21, 2025
Learning and Text Generation in Large Language Models
123B1E140 Riya Deshmukh
123B1E138 Om Dalvi
123B1E152 Nikhil Patil
Artificial Intelligence (AI) has revolutionized the way we interact with technology, and Generative Pre-trained Transformers (GPT) are at the forefront of Natural Language Processing (NLP). From chatbots and content creation to coding assistants, GPT models have transformed automation and human-like communication. But how do they actually work? Let’s explore the science behind GPT and how large language models learn and generate text.

1. Understanding the Transformer Architecture
In contrast to traditional Recurrent Neural Networks (RNNs) or Long Short-Term Memory (LSTM) networks, Transformers use self-attention, which allows them to process all words in a sentence simultaneously rather than word-by-word. This is a major improvement over RNNs, which struggle with long-range dependencies in text.
Key Characteristics of Transformers:
· Self-Attention: Each word in the input sequence can "attend" to every other word, effectively determining its relevance in context.
· Parallel Processing: Unlike RNNs, which process one word at a time, Transformers can handle entire sequences simultaneously, leading to faster processing.

2. The Training Process: Pre-training and Fine-tuning
GPT models are trained in two primary phases: Pre-training and Fine-tuning.
· Pre-training:
In this phase, the model learns from vast amounts of text data without any specific task in mind. The objective is to predict the next word in a sequence, allowing the model to build a foundation in grammar, factual knowledge, and relationships between words. The dataset used is often scraped from a wide range of sources such as books, websites, and other written texts.
· Fine-tuning:
After pre-training, the model undergoes supervised fine-tuning on task-specific datasets. This stage helps adapt the model to specific applications like:
o Question-Answering: For use in virtual assistants.
o Sentiment Analysis: For understanding the emotional tone of text.
o Creative Writing: For generating stories, poems, and more.
3. The Role of Self-Attention in Contextual Understanding
Self-attention is crucial in enabling GPT models to understand context. By computing attention scores, the model can decide which words are important to each other, even across long distances in a sentence. For instance, in a sentence like “The cat sat on the mat because it was tired,” the model understands that “it” refers to “the cat” rather than “the mat” because of the attention mechanism.
Self-attention is calculated through the following steps:
· Query, Key, and Value: Each word is converted into three vectors—Query, Key, and Value.
· Attention Score: These vectors are used to compute the attention score that determines the relevance of each word to every other word in the sequence.
4. Tokenization: The First Step in Text Processing
Before any text can be processed by GPT, it must be tokenized. Tokenization breaks the text into smaller units, called tokens, which may represent words, subwords, or even characters.
Common Tokenization Techniques:
· Word-based Tokenization: Each word is treated as a token.
· Subword-based Tokenization: Words are broken down into smaller subword units (e.g., "unhappiness" → "un", "happiness").
· Character-based Tokenization: Each individual character is treated as a token.
This tokenization ensures that the model understands semantic relationships between tokens.
5. Generating Text: The Prediction Mechanism
During text generation, GPT models rely on a multi-step process to generate coherent and contextually relevant text.
Step-by-Step Process:
Input Encoding: The model receives a prompt, which is tokenized and converted into numerical representations.
Probability Distribution: Based on the input, the model predicts the next most likely token using a probability distribution.
Sampling Techniques: To control creativity and diversity in the output, methods like Greedy Decoding, Beam Search, and Temperature Scaling are applied.
Greedy Decoding: Always selects the token with the highest probability.
Beam Search: Explores multiple sequences at once and chooses the most likely output.
Temperature Scaling: Controls randomness by adjusting the probabilities
Code: Generating Text Using GPT-2
from transformers import GPT2Tokenizer, GPT2LMHeadModel
import torch
def generate_text(prompt, model_name="gpt2", max_length=50):
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
input_ids = tokenizer.encode(prompt, return_tensors="pt")
output = model.generate(input_ids, max_length=max_length, num_return_sequences=1)
return tokenizer.decode(output[0], skip_special_tokens=True)
prompt = "Once upon a me"
generated_text = generate_text(prompt)
print(generated_text)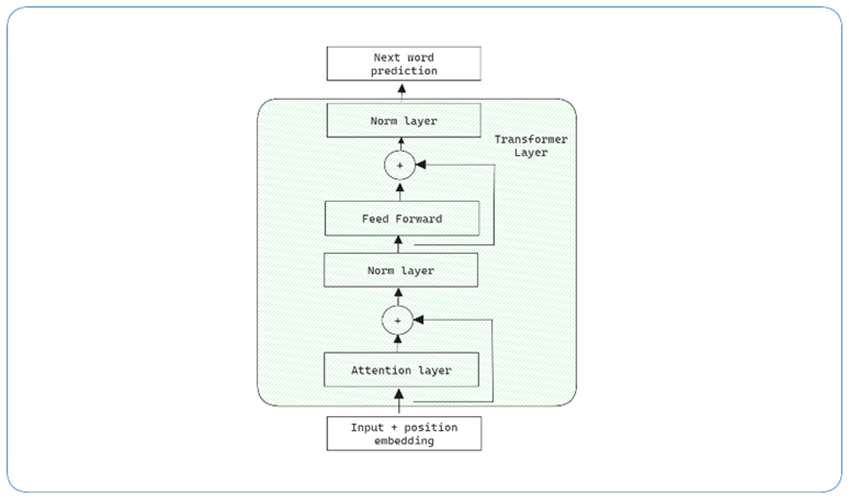
6. Challenges and Ethical Considerations
While GPT models are powerful, they come with several challenges and ethical concerns:
1. Bias in Training Data:
As GPT models are trained on large datasets scraped from the internet, they can inadvertently learn and amplify biases present in the data. This could lead to biased language generation, potentially reinforcing harmful stereotypes.
2. Misinformation:
GPT does not inherently validate facts. It generates text based on patterns, making it susceptible to generating misinformation, especially in domains requiring precise knowledge.
3. High Computational Cost:
Training large language models like GPT requires enormous computational resources, both in terms of hardware (e.g., GPUs) and energy consumption. This raises concerns about the environmental impact and accessibility of such models.
7. The Future of GPT and AI Models
The future of GPT and similar AI models holds exciting possibilities:
a. Smaller & Efficient Models:
New models like Mistral and LLaMA aim to make AI more accessible by being smaller, faster, and less computationally intensive. This could enable personal use cases and democratize AI.
b. Personal AI Assistants:
Future GPT models will be designed to learn from and adapt to individual user preferences, providing personalized interactions for tasks like scheduling, content creation, and even mental health support.
c. Multimodal AI:
Next-generation models will integrate not just text but also images, sound, and video, enabling richer, more interactive experiences.
d. AI Regulation & Ethics:
As AI becomes more pervasive, there will be an increased focus on regulatory frameworks to ensure ethical use, reduce biases, and protect privacy.
e. Scientific & Research Applications:
AI models will play a significant role in accelerating discoveries in areas like drug research, climate modeling, and automation.
f. AI-Augmented Creativity:
GPT-based models will assist in creative fields, helping artists, musicians, and game developers collaborate with AI to enhance human creativity.

8. Conclusion
GPT and other large language models represent a significant leap forward in AI-powered text generation. Their ability to comprehend and generate human-like text is grounded in the Transformer architecture, self-attention mechanisms, and massive pre-training datasets. While the technology offers enormous potential, addressing challenges like bias, misinformation, and computational efficiency will be critical for the future development of AI.


Excellent nikhil
👌
Nikhil patil gooood job🎊🎊
Nikhil patil good job 😘
Great