INTRODUCTION TO GENERATIVE AI: HOW LARGE LANGUAGE MODELS WORK
- Madhuri Pagale
- Mar 20, 2025
- 5 min read

Introduction to GEN AI
Artificial Intelligence (AI) is revolutionizing human-machine interactions, making digital
experiences more intuitive and efficient. Generative AI (Gen AI) is a subset of artificial
intelligence focused on creating new content, such as text, images, music, videos, and even
code. Unlike traditional AI, which primarily analyzes data and makes predictions, generative
AI can produce human-like content based on patterns learned from vast amounts of data.It
leverages deep learning techniques to generate realistic and high-quality content, often
indistinguishable from human-created content.
What is Generative AI?
Generative AI refers to artificial intelligence systems capable of generating new content,
including text, images, audio, video, and even code. These models rely on deep learning
techniques, particularly neural networks, to recognize patterns in vast datasets and produce
human-like responses. Generative AI is widely used for content creation, image synthesis,
music composition, and personalized AI interactions. The rise of large language models
(LLMs) such as GPT-4 has significantly contributed to the expansion of Generative AI,
making it a powerful tool for various applications.
What is LLM?
A Large Language Model (LLM) is a type of artificial intelligence (AI) model trained on
massive amounts of text data to understand, generate, and manipulate human language. These
models use deep learning techniques, particularly transformers, to process and generate
human-like text based on given prompts.Large Language Models (LLMs) play a crucial role
in Generative AI by enabling machines to understand, process, and generate human-like text.
LLMs are the backbone of many generative AI applications, allowing AI to create realistic and
meaningful content in various domains.
Difference Between Generative AI and LLM
While both Generative AI and LLM involve language processing, they serve distinct roles
and functions:
1. Generative AI and Large Language Models (LLMs) are closely related but serve
different purposes. Generative AI is a broad field, while LLMs are a specific type of
generative AI model designed for text-based applications
2. Generative AI: Uses various models like Transformers, GANs, VAEs, and Diffusion
Models depending on the content type
3. LLMs: Specifically use Transformer-based deep learning models to understand and
generate human-like text
4. Generative AI: AI-generated art, music composition, video synthesis, AI-driven
gaming characters, etc.
5. LLMs: Chatbots, content writing, summarization, translation, code generation, and
question-answering systems.
What is GPT?
GPT (Generative Pre-trained Transformer) is a state-of-the-art AI model developed by
OpenAI that specializes in understanding and generating human-like text. It is based on the
Transformer architecture, which allows it to process large amounts of textual data efficiently.
GPT undergoes pre-training on massive datasets and fine-tuning for specific applications,
making it highly effective in natural language understanding and text generation.
GPTpowered systems are widely used in chatbots, virtual assistants, AI-driven content
creation, and automated customer support.
How Large language model Work
A Large Language Model (LLM) is an advanced artificial intelligence system trained to
understand, generate, and manipulate human language using deep learning techniques. It
processes text inputs, learns patterns from vast datasets, and generates coherent and contually
relevant responses.


(A)Transformer Architecture
LLMs are built using a deep learning architecture called the Transformer, introduced in the
paper “Attention Is All You Need” (Vaswani et al., 2017). The Transformer enables models to
handle large amounts of text efficiently using a mechanism called self-attention.
(B) Training Data
LLMs are trained on massive datasets containing books, articles, websites, and other text
sources.
Some models are fine-tuned with human feedback (RLHF – Reinforcement Learning from
Human Feedback) to improve accuracy and relevance.
(C) Tokenization
Before processing, text is broken down into smaller units called tokens (words, subwords, or
characters).
Example:
Sentence: “The sky is blue.”
Tokens: [“The”, “sky”, “is”, “blue”, “.”]
Input Processing
The user provides a text prompt (e.g., “Explain how LLMs work”). The LLM tokenizes the
text and converts it into numerical representations (embeddings)
(Self-Attention Mechanism)
The model analyzes the input using the self-attention mechanism, which allows it to
understand the relationships between words in a sentence.
Example: In “The bat flew at night,” the model determines if “bat” means an animal or a
sports object based on surrounding words.
Key Features of LLMs
A)Attention Mechanism (Self-Attention & Multi-Head Attention)
Helps models understand context and relationships between words
Example: “Apple is a tech company” vs. “I ate an apple” – The model identifies different
meanings based on context.
B) Pre-training & Fine-tuning
Pre-training: The model learns general language understanding from vast datasets.
Fine-tuning: The model is trained on specific data for specialized tasks (e.g., legal AI, medical
AI).
C) Temperature & Randomness Control
Temperature setting controls response creativity:
Low (0.2-0.5) → More precise and factual responses.
High (0.7-1.0) → More creative and diverse responses.
Architecture of a Large Language Model (LLM)
The architecture of Large Language Models (LLMs) is based on the Transformer model,
which enables efficient processing of long text sequences. The key components of LLM
architecture include Tokenization, Embeddings, Multi-Layer Transformer Blocks, and Output
Generation.
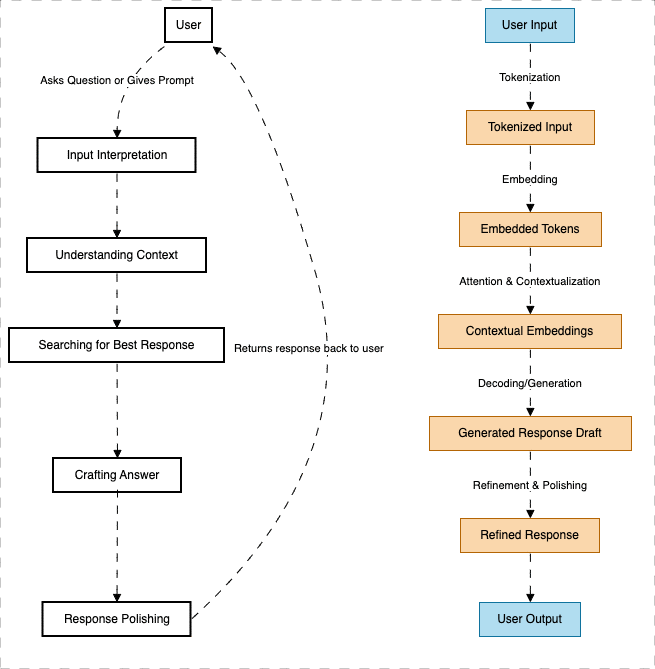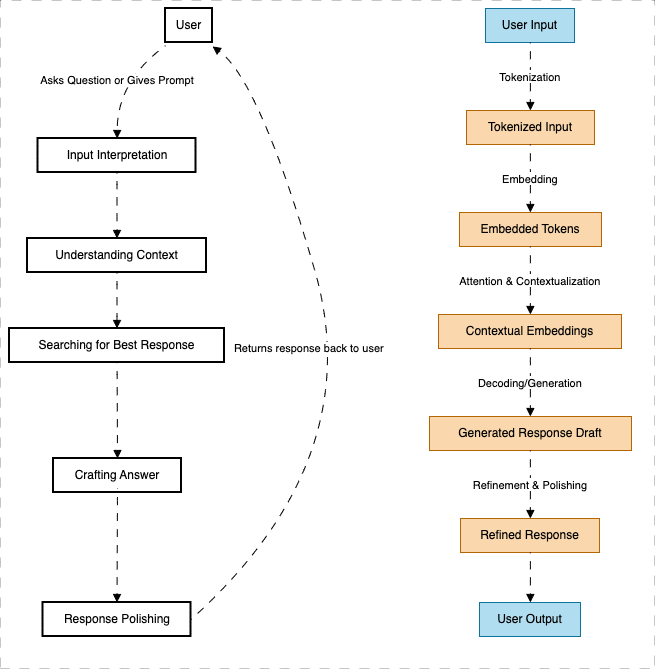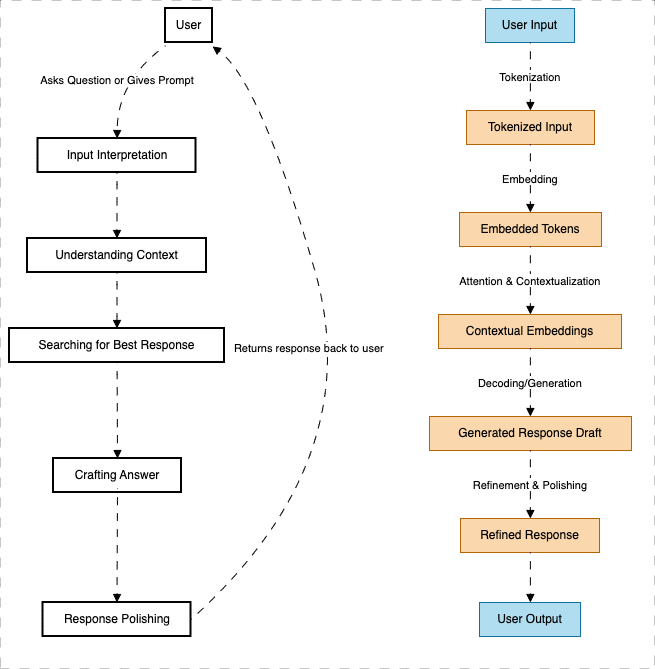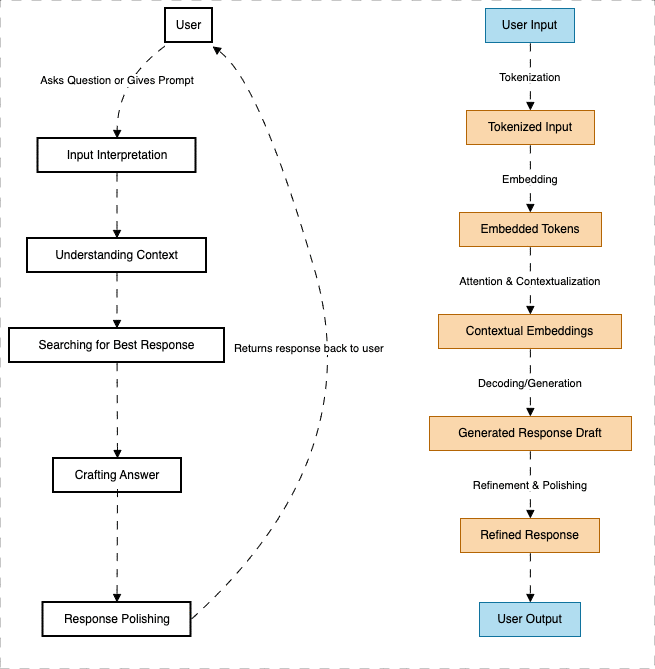
User Input (Prompt): The user provides text (e.g., “What is AI?”).
Tokenization: Converts words into numerical tokens for processing.
Embeddings: Transforms tokens into high-dimensional vectors.
Transformer Model (LLM Core):
Self-Attention: Determines the relationship between words.
Multi-Head Attention:Processes multiple aspects of context simultaneously.
Feedforward Neural Network: Enhances learning and prediction.
Text Generation: Predicts and generates the next best word(s) based on learned data.
Output: The final, human-readable response is returned to the user.
HOW LARGE MODEL IS TRAINED
1. Data Collection
Source of Data: LLMs are trained on a variety of datasets, including:
Text from websites (e.g., Wikipedia, books, forums)
Research papers
Code repositories
News articles and social media content
2.Data Preprocessing: Raw data is cleaned by:
Removing duplicates and irrelevant text.
Tokenizing (converting words into numerical representations).
Handling special characters and multiple languages.
3. Model Architecture
Transformer Model: LLMs are based on the transformer architecture, which uses:
Self-Attention Mechanism: Allows the model to focus on important parts of the input text.
Layers of Neurons: Deep networks with millions or billions of parameters.
Example: GPT (Generative Pre-trained Transformer) models use this structure.
4. Pre-training Process
Objective: Teach the model to understand and predict text patterns.
Methods:
Next Word Prediction (Causal Language Modeling): Predicts the next word in a sentence.
Masked Language Modeling (MLM): Predicts missing words in a sentence (e.g., BERT
model).
Training Data Flow:
1. Input text is tokenized and passed through the model.
2. The model guesses the next word or fills in blanks.
3. The difference between prediction and actual text (loss) is measured.
4. Weights (parameters) are adjusted using backpropagation and gradient descent.
5. Fine-Tuning (Optional)
After pre-training, the model can be specialized for tasks like:
Sentiment analysis
Chatbots
Medical or legal document analysis
Fine-tuning uses a smaller, domain-specific dataset to improve accuracy.
6. Evaluation and Deployment
Evaluation Metrics: Performance is tested using:
Perplexity: How well the model predicts the next word.
Accuracy: Correct predictions vs. total predictions.
Deployment: The trained model is optimized and made available via APIs or apps
Applications of LLMs:
• Virtual assistants (e.g., chatbots)
• Content creation (e.g., writing articles)
• Sentiment analysis
• Code generation
• Language translation
Challenges of LLMs:
• Bias and Fairness: May reflect biases present in training data.
• Ethical Concerns: Misuse for disinformation or generating deepfakes.
• Resource Intensive: Requires vast computing power for training and operation.
FLOWCHART
Conclusion
LLMs (Large Language Models) play a crucial role in Generative AI, enabling machines to
understand, process, and produce human-like text. Their ability to perform diverse tasks—
such as content generation, language translation, and conversational AI—has transformed
industries and user experiences.
While LLMs offer powerful capabilities, they also pose challenges like bias, ethical
concerns, and high resource consumption. With continuous advancements, LLMs are
expected to become more accurate, efficient, and responsible, driving innovation across various field


Comments