Exploring the Transformer Architecture: The Backbone of GPT and BERT
- Madhuri Pagale
- Mar 18, 2025
- 6 min read

Have you ever wondered how ChatGPT generates such human-like text? Or how Google's search engine suddenly got so much better at understanding your questions? The secret behind these advances is a revolutionary AI architecture called the Transformer. In this blog, we'll break down this game-changing technology in a way anyone can understand, while still providing enough depth for the tech-savvy reader.
From Robots to Conversations: The Transformer Revolution
Before 2017, AI language models were like robots reading books one word at a time, struggling to remember what they read a few paragraphs ago. Enter the Transformer architecture, which changed everything by allowing AI to look at entire sentences at once, like a human scanning a page and making connections between different parts.
This shift from reading word-by-word to understanding context across a whole passage is what enables today's AI to have conversations that feel natural, translate between languages with impressive accuracy, and even write creative content.
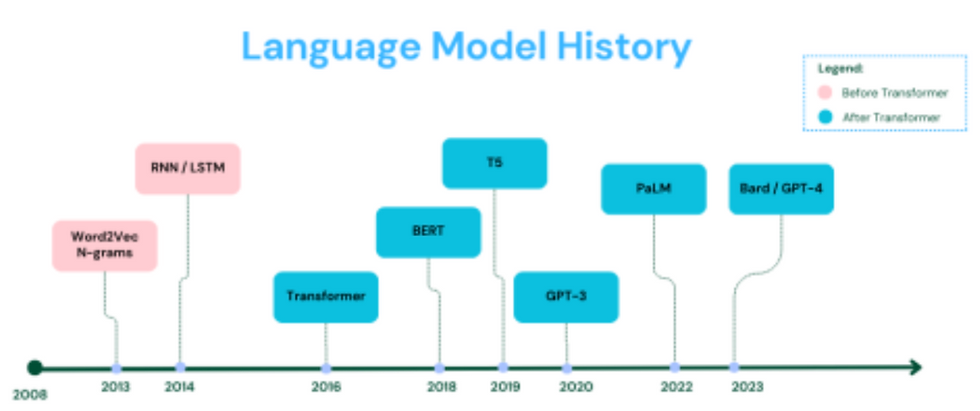
The Journey to Smarter AI: A Brief History
Remember when talking to a computer felt like speaking to someone who barely understood your language? Here's how we got from there to here:
In the early days, researchers had to manually program rules for language. Then came neural networks that could learn from data but processed text one word at a time, like reading with a finger under each word. These models (called RNNs and LSTMs) were revolutionary but still had a fundamental limitation - they couldn't easily connect words that were far apart in a sentence.
In 2017, a group of researchers published a paper with the bold title "Attention is All You Need," introducing the Transformer architecture. The key insight? Let the model look at all words in a sentence simultaneously and figure out which ones should be connected.
This breakthrough is like the difference between someone who has to read a mystery novel linearly versus someone who can flip through pages, connecting clues from chapter 1 with revelations in chapter 10.
Under the Hood: How Transformers Work
Think of the Transformer as a series of specialized tools working together. Let's break down these tools in plain language:
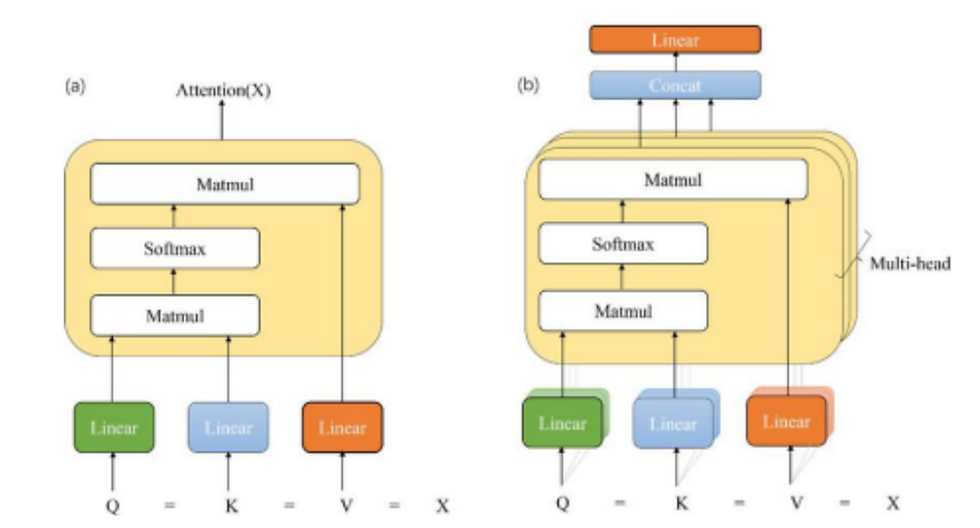
1. The Attention Mechanism: The Magic of Connections
Imagine you're at a party where everyone is talking. Your brain naturally filters conversations, paying attention to relevant ones while tuning out others. The "self attention" mechanism in Transformers works similarly.
When a Transformer reads the sentence "The animal didn't cross the street because it was too wide," it needs to figure out what "it" refers to. Is it the animal or the street? The self-attention mechanism helps it weigh the connection between "it" and other words, understanding that "it" likely refers to "street" in this context.

import torch
import math
def scaled_dot_product_attention(query, key, value, mask=None):
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9) attn = torch.softmax(scores, dim=-1)
output = torch.matmul(attn, value)
return output, attn
# Example usage
batch_size, seq_len, d_model = 2, 5, 64
query = torch.rand(batch_size, seq_len, d_model)
key = torch.rand(batch_size, seq_len, d_model)
value = torch.rand(batch_size, seq_len, d_model)
output, attention_weights =
scaled_dot_product_attention(query, key, value)
print("Attention Output Shape:", output.shape)
2. Multi-Head Attention: Looking from Different Angles
Have you ever had a conversation where you picked up on both the words and the tone of voice? Multi-head attention is similar - it lets the model examine the text from multiple perspectives simultaneously.
One "head" might focus on grammar, another on subject-verb relationships, and another on broader context. This multi-perspective approach gives the model a richer understanding of language.

import torch.nn as nn
class MultiHeadAttention(nn.Module):
def init(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
self.d_k = d_model // num_heads
self.num_heads = num_heads
self.linear_q = nn.Linear(d_model, d_model) self.linear_k = nn.Linear(d_model, d_model) self.linear_v = nn.Linear(d_model, d_model)
self.linear_out = nn.Linear(d_model, d_model)
def forward(self, query, key, value, mask=None): batch_size = query.size(0)
# Linear projections and reshape into multiple heads
query = self.linear_q(query).view(batch_size, -1, self.num_heads, self.d_k).transpose(1,2)
key = self.linear_k(key).view(batch_size, -1, self.num_heads, self.d_k).transpose(1,2)
value = self.linear_v(value).view(batch_size, -1, self.num_heads, self.d_k).transpose(1,2)
# Scaled dot-product attention on all heads
attn_output, attn_weights =
scaled_dot_product_attention(query, key, value, mask)
# Concatenate heads and pass through final linear layer
attn_output =
attn_output.transpose(1,2).contiguous().view(batch_size, -1, self.num_heads * self.d_k)
output = self.linear_out(attn_output)
return output
# Example usage
d_model = 64
num_heads = 8
mha = MultiHeadAttention(d_model, num_heads)
output = mha(query, key, value)
print("Multi-Head Attention Output Shape:", output.shape)
3. Positional Encoding: Words in Order
If I rearranged the words in this sentence, meaning the change would completely. Since Transformers process all words at once, they need a way to know word order. Positional encoding embeds location information into each word, preserving the sequence without forcing sequential processing.
class PositionalEncoding(nn.Module):
def init(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__() pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len,
dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position div_term) pe[:, 1::2] = torch.cos(position div_term) pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:, :x.size(1)]
return x
# Example usage
pos_encoder = PositionalEncoding(d_model)
sample_input = torch.rand(batch_size, seq_len, d_model) encoded_input = pos_encoder(sample_input)
print("Encoded Input Shape:", encoded_input.shape)
The Dynamic Duo: BERT and GPT



The Transformer architecture spawned two famous AI families that approach language in complementary ways:
BERT: The Understanding Specialist
BERT (Bidirectional Encoder Representations from Transformers) reads text in both directions at once, like how you might scan back and forth through a complex paragraph to fully understand it. Google uses BERT to better understand search queries, focusing on what you really mean rather than just matching keywords.
from transformers import BertTokenizer, BertModel
# Load pre-trained BERT model and tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') model = BertModel.from_pretrained('bert-base-uncased')
# Encode text
text = "Transformers are revolutionizing natural language processing."
inputs = tokenizer(text, return_tensors="pt")
outputs = model(**inputs)
print("BERT Last Hidden State Shape:",
outputs.last_hidden_state.shape)
BERT excels at:
● Understanding sentiment in reviews
● Answering questions based on text passages
● Classifying content by topic
● Finding named entities (people, places, organizations) in text
GPT: The Writing Assistant
GPT (Generative Pre-trained Transformer) specializes in generating coherent text. It reads contextually from left to right, much like how humans write and read. Each word it generates builds on previous words, creating coherent text that can range from business emails to creative stories.
GPT powers applications like:
● AI writing assistants
● Chat interfaces
● Content creation tools
● Code completion systems
Transformers in Real Life: Beyond the Hype
Transformers aren't just academic curiosities - they're changing how we interact with technology daily:
● When you email a colleague in another country, translation systems powered by Transformers help bridge the language gap.
● As you write a document, AI writing assistants suggest completions and improvements.
● When you search for information, search engines use Transformer models to understand your query better.
● Customer service chatbots increasingly use these models to handle queries more naturally.
A friend who runs a small business recently told me how a Transformer-based tool analyzed thousands of customer reviews in minutes, identifying product issues that would have taken weeks to find manually. That's the practical impact of this technology.
The Reality Check: Challenges and Limitations
Like any technology, Transformers have their challenges:
The Power Problem
Training these models requires enormous computing power. GPT-3, with its 175 billion parameters, reportedly cost millions of dollars to train. This raises questions about who can afford to develop these technologies and the environmental impact of the energy consumed.
The Data Dilemma
Transformers learn from vast amounts of text from the internet, absorbing both the good and bad. Researchers continue working on ways to ensure these models don't perpetuate biases or generate harmful content.
The Black Box Mystery
Despite our best efforts, we still don't fully understand how these models make specific decisions. It's like having a brilliant colleague who can't explain their thought process - helpful but sometimes frustrating.
What's Next? The Future of Transformer Technology
Researchers aren't sitting still. They're already addressing these challenges with innovations like:
● Smaller, more efficient models that run on your phone instead of data centers ● Specialized Transformers that excel at specific tasks while using fewer resources
● Hybrid approaches that combine Transformers with other techniques for better results
Bringing It All Together
The Transformer architecture isn't just another incremental improvement in AI - it represents a fundamental shift in how machines process language. By enabling computers to better understand context and generate more human-like text, these models are bridging the gap between human and machine communication.
Whether you're a developer looking to build the next great app, a business leader exploring AI solutions, or simply someone curious about how technology is evolving, understanding Transformers gives you insight into the forces shaping our digital future.
The next time you chat with an AI assistant or watch a machine translation that captures nuance you thought only humans could understand, remember the elegant architecture
making it possible - the Transformer, quietly revolutionizing how we interact with technology.
Want to Learn More?
If you're curious to dive deeper:
● The Illustrated Transformer - A visual explanation that makes the concepts clearer
● BERT Research Paper - For those who want to explore the technical details ● HuggingFace Transformers - Tools to experiment with these models yourself
Name : Kshitij Hedau , Mandar Sewalkar, Dheer Parekh
PRN no : 123B1E167,123B1E158,123B1E166
Div : ENTC-C


Great work 👏 👍🏻
Awesome
Very helpful!!
Nice!!
Interesting!!!!