Evolution of GPT Models: From GPT-1 to GPT-4 and Beyond
- Madhuri Pagale
- Mar 19, 2025
- 12 min read

Written By:
Surabhi Jahagirdar
Shraddha Vidhate
Sanchita Dhole
Evolution of GPT Models: From GPT-1 to GPT-4 and Beyond
Introduction
The Generative Pre-Trained Transformer (GPT) fashions by means of OpenAI have revolutionized the field of natural language processing (NLP). GPT models have set a new benchmark for versatility in NLP by means of performing numerous duties which includes textual content era, query answering, summarization, and so forth. — without requiring venture-specific supervised education.
GPT models surely stand out due to the fact they carry out pretty nicely with minimal enter information, frequently requiring few examples or none. This great, referred to as few-shot or maybe zero-shot getting to know, allows GPT models to generalize across duties they have got in no way encountered for the duration of schooling.

In this article, we are able to explore the evolution of GPT models and talk how they’ve superior the field of NLP:
1. The groundbreaking principles introduced with GPT-1, laid the inspiration for huge-scale pre-trained language models.
2. The leap ahead was made via GPT-2, which validated the potential of unsupervised multitask getting to know.
3. The incredible upgrades of GPT-3 set new requirements with its few-shot learning competencies.
4. The today's milestone GPT-4, has extended abilities even similarly, enhancing in areas like protection, controllability, multilingual know-how, and the capacity to technique and cause over complex data.

1.GPT-1: The Foundation of Generative Pre-training :
In 2018, OpenAI introduced Generative Pre-trained Transformer 1 (GPT-1), a model that revolutionized natural language processing (NLP). This innovation was documented in the research paper “Improving Language Understanding by Generative Pre-Training.” GPT-1 marked a major shift in NLP by demonstrating the effectiveness of large-scale unsupervised pre
training, followed by fine-tuning for specific tasks.
Prior to GPT-1, state-of-the-art NLP models relied primarily on supervised learning, requiring vast amounts of annotated data for different tasks such as sentiment analysis, question answering, and textual entailment. GPT-1 challenged this approach by proving that a pre-trained generative language model could effectively generalize across multiple tasks with minimal supervision.
Core Concepts:
GPT-1 introduced a semi-supervised learning framework consisting of two key phases: 1. Unsupervised Pre-training: The model was trained on a large text corpus to learn language patterns, sentence structures, and word relationships. This phase involved predicting the next word in a sequence, enabling the model to grasp syntactic and semantic nuances.
2. Supervised Fine-tuning: After pre-training, the model was fine-tuned on specific NLP tasks using smaller labeled datasets. Unlike traditional supervised models, GPT-1 leveraged its prior linguistic knowledge, requiring fewer labeled examples to achieve strong performance.
By integrating pre-training and fine-tuning, GPT-1 laid the groundwork for future language models, influencing the development of more advanced AI systems such as GPT-2, GPT-3, and GPT-4.
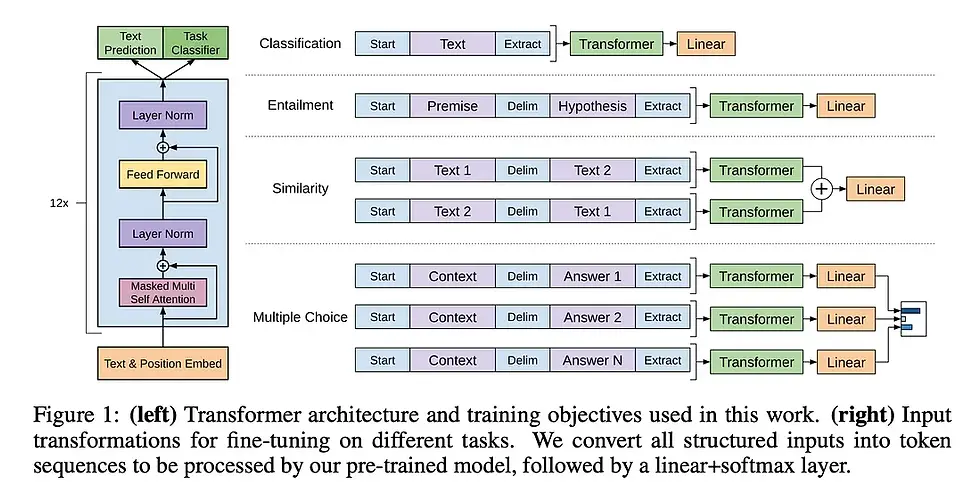
GPT-1: Model Architecture and Dataset
GPT-1 is built on a 12-layer decoder-only transformer architecture utilizing masked self-attention. This mechanism ensures that the model only considers previous tokens in a sequence, allowing it to generate text while maintaining contextual coherence. It is based on the Transformer model originally introduced by Vaswani et al.
Key Architectural Features
• Composed of 12 transformer layers, each containing 12 attention heads. • Uses a 768-dimensional state for token embeddings and positional encodings. • Incorporates a 3072-dimensional hidden state in the feed-forward network. • Employs Byte Pair Encoding (BPE) with a vocabulary size of 40,000 merges for efficient tokenization.
• Regularization techniques include dropout (0.1) and modified L2 regularization to prevent overfitting.
• Optimized using the Adam optimizer with a learning rate of 2.5e-4, trained over 100 epochs with mini-batch sizes of 64 and a sequence length of 512 tokens.
Training Dataset
• The model was pre-trained on the BooksCorpus dataset, which consists of 7,000 unpublished books. The dataset provided long, continuous text passages, enabling the model to develop an understanding of long-range dependencies in language. Unlike smaller, fragmented datasets, this allowed GPT-1 to capture deeper linguistic structures.
• For supervised fine-tuning, GPT-1 required very few training epochs—sometimes as few as three—to adapt to specific natural language processing (NLP) tasks. This highlighted the strength of the unsupervised pre-training stage, where the model had already acquired broad linguistic knowledge, requiring only slight refinements for task-specific applications.
Performance and Achievements
GPT-1 exceeded initial expectations, outperforming specialized supervised models on 9 out of 12 tasks in the GLUE benchmark (General Language Understanding Evaluation). The model demonstrated remarkable zero-shot learning capabilities, excelling in tasks such as: • Question answering
• Sentiment analysis
• Schema resolution
This success laid the foundation for future pre-trained language models, demonstrating that a generative language model could be fine-tuned for multiple tasks with minimal additional training.
Key Contributions
• Task Generalization: Showed that a single pre-trained model could be adapted to various NLP tasks.
• Few-shot and Zero-shot Learning: Although GPT-1 required fine-tuning, it paved the way for later models to handle tasks with minimal or no training data.
• Efficiency in Training: Proved that unsupervised pre-training reduces reliance on large, annotated datasets, making NLP models more scalable and adaptable.
GPT-1's transformative approach laid the groundwork for more advanced successors like GPT-2, GPT-3, and GPT-4, shaping the future of AI-driven language models.
GPT-1 Model Breakdown:
1. Token Embedding – Converts words into vector representations using Byte Pair Encoding (BPE).
2. Positional Encoding – Adds positional information to tokens to maintain word order.
3. Transformer Blocks (12 Layers):
o Multi-Head Attention – Focuses on different parts of input text.
o Layer Normalization – Stabilizes training and improves efficiency.
o Feed-Forward Network – Processes refined contextual information.
o Residual Connections – Helps with gradient flow and prevents degradation.
4. Output Layer – Applies softmax to predict the next token in text generation.
1. Token Embedding (BPE Tokenization) :

2. Positional Encoding

3. Multi-Head Self-Attention

4. Transformer Block

5. Output Layer (Next Token Prediction)

2. GPT-2: Advancing Unsupervised Multitask Learning with Scale:
Building on the success of GPT-1, OpenAI introduced GPT-2 in 2019, detailed in the research paper “Language Models are Unsupervised Multitask Learners.” This model significantly expanded upon its predecessor by increasing both model size and training data, demonstrating the power of large-scale pretraining.
Key Innovations in GPT-2
• Multitask Learning through Task Conditioning: Unlike traditional models that require separate training for different tasks, GPT-2 enabled a single model to perform multiple tasks using the same architecture. By conditioning outputs based on input context and task requirements, it could adapt to different scenarios, laying the groundwork for zero-shot learning.
• Zero-Shot Learning & Task Transfer: One of GPT-2’s standout features was its ability to understand task instructions in natural language and generate responses without explicit
task-specific fine-tuning. This allowed the model to handle tasks such as translation, summarization, and question-answering without prior training on those specific datasets.
Architecture and Dataset
GPT-2 brought significant improvements in size and complexity compared to GPT-1:
• Increased Model Size: With 1.5 billion parameters (compared to GPT-1’s 117 million), GPT-2 demonstrated that scaling up significantly improves performance.
• Enhanced Architecture: It utilized 48 transformer layers, 1600-dimensional embeddings, and an extended vocabulary of 50,257 tokens.
• Larger Context Window: The model could process sequences of up to 1024 tokens, allowing it to handle longer and more coherent text generation.
• Optimization Techniques:
o Layer normalization was shifted to the input of each sub-block, with an extra normalization step added after the final self-attention layer.
o Residual connections were scaled using 1/N1/\sqrt{N}1/N (where N is the number of layers) to enhance stability.
o Byte Pair Encoding (BPE) improved handling of rare words and out-of-vocabulary tokens.
To analyze the impact of scaling, OpenAI trained multiple versions of GPT-2, including models with 117M, 345M, 762M, and 1.5B parameters. Results confirmed that larger models consistently exhibited lower perplexity, reinforcing the idea that increasing model size improves performance.
Training-Dataset–WebText:
GPT-2 was trained on WebText, a dataset consisting of high-quality text from 8 million documents (around 40GB of data), sourced from Reddit discussions. Wikipedia content was intentionally excluded to avoid data leakage into common evaluation benchmarks.
Performance and Breakthroughs
• Achieved state-of-the-art results on 7 out of 8 language modeling benchmarks, particularly excelling in tasks that required understanding long-range dependencies (e.g., LAMBADA dataset).
• Demonstrated strong comprehension skills in the Children’s Book Test (CBT), improving noun and named entity recognition.
• Performed well in zero-shot reading comprehension and language translation (French to English), though it didn’t surpass supervised models in translation.
• Showcased a log-linear relationship between model size and performance, where increasing parameters led to consistently lower perplexity, proving that scaling enhances language understanding.
These advancements paved the way for even larger models like GPT-3, reinforcing the importance of scaling in deep learning.
3. GPT-3: Advancing AI with Few-Shot Learning
In 2020, OpenAI introduced GPT-3, marking a major milestone in artificial intelligence. This model, with an astounding 175 billion parameters, surpassed its predecessor in both scale and capability. What set GPT-3 apart was its ability to perform complex tasks without specific fine tuning, demonstrating a strong grasp of few-shot and zero-shot learning. By interpreting instructions within the input, it could generate responses with minimal examples, making it highly adaptable across different domains.
Key Innovations in GPT-3
• In-Context Learning: Understanding Without Re-Training :GPT-3 introduced in context learning, allowing it to process tasks by recognizing patterns in the input rather than requiring additional model training. This meant that the model could adapt to new tasks on the fly, simply by being provided with relevant prompts and examples. Unlike earlier AI systems, which needed to be retrained for each new function, GPT-3 could dynamically adjust its output based on context alone.
• Few-Shot, One-Shot, and Zero-Shot Learning :One of GPT-3’s defining strengths was its flexibility in learning approaches:
o Few-shot learning: The model was given a handful of examples and could generate accurate responses by following the observed pattern.
o One-shot learning: Even with just one example, it could understand and execute a task.
o Zero-shot learning: Without any direct examples, the model could still complete tasks based solely on provided instructions.
By leveraging its extensive dataset and massive parameter count, GPT-3 became highly adaptable across multiple industries, from content generation to programming and even logical reasoning.
Technical Advancements & Model Architecture
GPT-3 retained the fundamental transformer-based architecture of its predecessor but introduced several significant improvements:
Expanded Parameters: 175 billion parameters distributed across 96 layers, significantly enhancing processing power.
Higher-Dimensional Word Embeddings: Increased to 12,888 dimensions, enabling deeper contextual understanding.
Extended Context Window: Doubled from 1,024 tokens (GPT-2) to 2,048 tokens, allowing the model to retain and analyze longer sequences of text.
Optimized Training Algorithm: Utilized the Adam optimizer with fine-tuned settings (β₁ = 0.9, β₂ = 0.95, ε = 10⁻⁸) for improved learning efficiency.
Advanced Attention Mechanisms: Featured dense and locally banded sparse attention, enhancing its ability to focus on different sections of input data more effectively.
Diverse Training Data: The Backbone of GPT-3
To maximize its understanding of human language, GPT-3 was trained on an extensive and diverse dataset. The model learned from multiple high-quality sources, including:
• Common Crawl (a vast collection of internet text)
• WebText2 (selected web content)
• Books1 & Books2 (published literature)
• Wikipedia (structured general knowledge)
By prioritizing higher-quality datasets during training, GPT-3 was able to develop a rich vocabulary, strong contextual awareness, and improved coherence in text generation. The total dataset exceeded 570GB of text, making it one of the most extensively trained AI models at the time.
Performance & Real-World Applications
GPT-3 demonstrated exceptional performance across multiple language-processing benchmarks, often surpassing previous AI models in tasks requiring adaptability.
❖ Text Generation & Summarization: The model could produce coherent, human-like essays, articles, and summaries without explicit task-specific training.
❖ Machine Translation & Conversational AI: It could translate languages, assist in chatbot development, and improve automated responses.
❖ Logical & Mathematical Reasoning: GPT-3 showed competency in basic arithmetic, pattern recognition, and problem-solving when prompted correctly.
❖ Code Generation & SQL Queries: It could generate programming scripts, SQL queries, and structured data outputs, aiding software development.
By eliminating the need for separate training on each new task, GPT-3 significantly reduced development time for AI applications, making it a game-changer in natural language processing.
Why GPT-3 Redefined AI
Unlike earlier models, GPT-3 could analyze and generate text dynamically, adapting to various fields without additional fine-tuning. Its ability to engage in zero-shot, one-shot, and few-shot learning made it incredibly versatile. Industries ranging from content creation and education to programming and business automation rapidly adopted GPT-3, proving its real-world impact.
The advancements introduced in GPT-3 set the stage for future models, ultimately paving the way for the development of GPT-4 and beyond.
4. GPT-4: Advancing AI Towards General Intelligence
In 2023, OpenAI introduced GPT-4, marking a significant leap in artificial intelligence. As outlined in the GPT-4 Technical Report, this model expanded upon the foundation of its predecessors, offering more refined language processing, improved accuracy, and the ability to handle increasingly complex tasks across a wide range of disciplines.
Key Innovations in GPT-4
• Multimodal Capabilities: Integrating Text and Images: Unlike previous models that were solely text-based, GPT-4 introduced multimodal capabilities, allowing it to process both text and images as inputs. This advancement enabled the model to interpret and analyze visual content alongside written language. As a result, GPT-4 could effectively perform tasks such as image captioning, visual question answering, and diagram analysis, significantly broadening its real-world applications.
• Enhanced Reasoning and Expanded Context Window: GPT-4 demonstrated notable improvements in logical reasoning and long-context comprehension. One key enhancement was the increase in context length, allowing the model to retain and analyze larger volumes of information over extended conversations or documents. This made GPT
4 particularly valuable for tasks like legal document analysis, long-form summarization, and complex discussions that required maintaining context over multiple exchanges. • Reduction in Hallucinations and Bias Mitigation: A major challenge with earlier versions like GPT-3 was the generation of misleading or factually incorrect outputs, known as hallucinations. GPT-4 addressed this issue by implementing more advanced filtering mechanisms, improving the reliability of its responses. Additionally, OpenAI introduced bias mitigation techniques to minimize the model’s reinforcement of stereotypes, resulting in more ethical and balanced outputs.
Technical Improvements & Model Architecture
While OpenAI has not publicly disclosed all architectural details of GPT-4, several key advancements have been observed:
• Higher Parameter Efficiency: Unlike previous iterations, GPT-4 focused on better performance without merely increasing the number of parameters, making it more efficient.
• Sparse Activation Techniques: Rather than using the entire network for every task, GPT 4 employed sparsity techniques, meaning different parts of the model were activated depending on the task at hand. This significantly improved processing efficiency.
• Multimodal Integration: The architecture expanded beyond pure text-based processing, embedding both text and image-processing capabilities for more dynamic AI interactions.
GPT-4’s training data was also more diverse and refined, incorporating higher-quality text sources and multimodal datasets. Unlike previous models, its dataset selection strategy aimed to enhance accuracy, reduce biases, and improve contextual understanding across a wider range of topics.
Performance & Real-World Applications
GPT-4 outperformed previous models in multiple areas, setting new industry standards for natural language processing, reasoning, and multimodal tasks:
• Advanced Human-Like Reasoning: The model demonstrated stronger logical thinking and problem-solving abilities, particularly in tasks that required synthesizing information across different domains, such as scientific research or multilingual translations.
• Superior Few-Shot and Zero-Shot Learning: While GPT-3 introduced few-shot learning, GPT-4 improved upon it, excelling in zero-shot learning, where it successfully performed tasks with little to no prior examples.
• Multimodal Adaptability: Thanks to its ability to process images as inputs, GPT-4 tackled complex visual-linguistic tasks, such as interpreting charts, generating image descriptions, and answering questions based on visual data.
Challenges & Ethical Considerations
Despite its advancements, GPT-4 also presented several limitations and ethical challenges:
• High Computational Demand: Training and deploying GPT-4 required immense computational resources, raising concerns about energy consumption and environmental impact.
• Bias in AI Outputs: Since the model learns from human-generated data, it inherited biases present in its training material. While OpenAI introduced mitigation strategies, eliminating bias entirely remains an ongoing challenge.
• Generalization vs. Specialized Expertise: While GPT-4 excelled at general reasoning and pattern recognition, it could not always match the expertise of specialized AI models trained for domain-specific tasks, such as medical diagnosis or scientific research.
The Road Ahead: Towards General Intelligence
GPT-4 represented a major step forward in AI, but it also highlighted the challenges of building models that are both powerful and responsible. As AI continues to evolve, the focus will likely shift toward enhancing efficiency, minimizing biases, and improving real-world applications. The development of future models will play a crucial role in shaping the future of AI-driven interactions.
Summary Table for GPT Models
Feature | GPT-1 (2018) | GPT-2 (2019) | GPT-3 (2020) | GPT-4 (2023) |
Paper Title | "Enhancing Language Understanding via Generative Pre-training" | "Unsupervised Multitask Learning in Language Models" | "Few-Shot Learning in Language Models" | "Technical Report on GPT-4" |
Parameters | 117M | 1.5B | 175B | Undisclosed (larger than GPT-3) |
Architecture | 12-layer transformer | 48-layer transformer | 96-layer transformer | Optimized with multimodal capabilities |
Context Window | 512 tokens | 1024 tokens | 2048 tokens | Up to 32,000 tokens |
Key Advancements | Generative pre training | Multitask learning | Few-shot & in-context learning | Multimodal reasoning (text & images) |
Multimodal Support | No | No | No | Yes (text + images) |
Applications | Required fine tuning | Improved multitasking | Human-like text, code, translations | AI assistants, education, research |
Challenges | Limited generalization | Struggled with summarization | Resource intensive, ethical concerns | High cost, ethical & generalization issues |
Conclusion:
The evolution of GPT models, from GPT-1 to GPT-4, showcases significant advancements in natural language processing. Each iteration introduced improved learning capabilities, from few-shot learning in GPT-1 to multimodal reasoning in GPT-4. These models have transformed AI applications across various fields. However, challenges like ethical concerns and computational demands remain, highlighting the need for ongoing improvements.
References:
Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving Language Understanding by Generative Pre-Training. OpenAI. Retrieved from: OpenAI GPT-1 Paper
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., ... & Amodei, D. (2020). Language Models are Few-Shot Learners. OpenAI. Retrieved from: GPT-3 Paper
OpenAI. (2023). GPT-4 Technical Report. Retrieved from: GPT-4 Report
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language Models are Unsupervised Multitask Learners. OpenAI. Retrieved from: GPT-2 Paper


👍🏻
Great blog. Easy to understand, helpful and yet informative.
Nice blog Learned a lot from it
well done ! very nice information
well written, Impressive, informative