Comparing Large Language Models: GPT vs. BERT vs. T5
- Madhuri Pagale
- Mar 19, 2025
- 6 min read

Written By:
Mukta Mali
Komal Tile
Pravinya Bairagi
Comparing Large Language Models: GPT vs. BERT vs. T5
Introduction to Large Language Models (LLMs)
LLMs stands for Large Language Models which are a group of models of artificial intelligence. To understand and generate text in human language they are trained on huge datasets of text. LLMs contains deep learning techniques and primarily based on neural networks generate text. The NLPs foundation is based on language models. They have task like a text summarization, question-answering, machine translation. For example, popular LLMs are GPT, BERT and T5. Each of these models have different architectures and uses that make them suitable for various other Natural Language Processing tasks.

GPT
(Generative Pre-trained Transformer)
Introduction to GPT
Generative Pre-trained Transformer that is GPT is create by Open ai which is basically deep learning model especially used for Natural Language Processing. GPT predicts next word of sequence based on a transformer architecture which generates text like a human text. By training on large data sets GPT can perform text generation, text translation, speech recognition efficiently. It is mainly used for applications of natural language processing like text generation. GPT learns different text patterns from large datasets of text, unlike other models. As these models are based on hard-coded rules or fixed templates.

GPT Architecture
The architecture of GPT is based on the transformer model and comprises a number of necessary layers combined:
Input Embedding: Input data is fed, and it Converts input words into numerical vector representations for next process.
Positional Encoding: It adds information of position to embeddings to enable the model to maintain word order.
Dropout Layer: If noise data is present, then model is overfitted it give incorrect output, so this layer is used to avoid overfitting. Here unwanted neurons are dropout.
Transformer Layers: It consists of sequence of multiple transformer blocks, each of having:
Multi-Head Self-Attention Mechanism: It helps the model in attending to various words in the input text to enhance context awareness.
Feedforward Neural Network: It processes and fine-tunes the attended information. It uses the RELU activation function.
Layer Normalization: This layer avoids gradient-related problems and make possible of stable training.
Linear Layer: Transforms the processed transformer output into logits for predicting the next word.
SoftMax Layer: In this layer it generates probability distributions for next tokens, ensuring reasonable text generation.
This modular design allows GPT to comprehend and produce human-like text effectively.



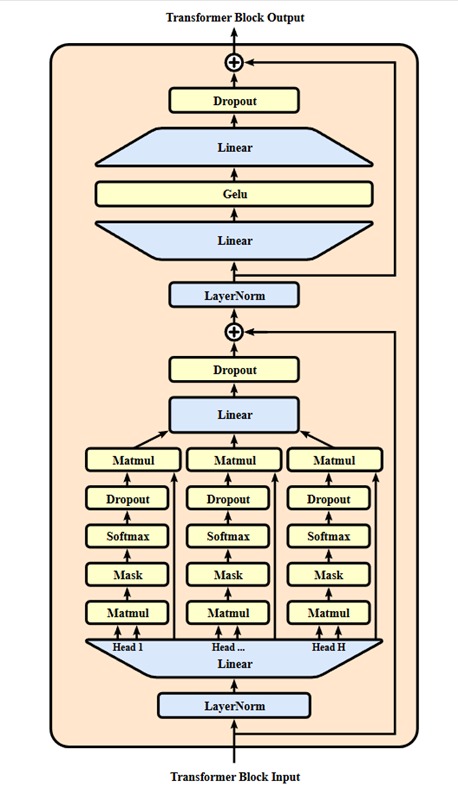
Fig.1 Architecture of the GPT Model
Key GPT variants:
1. GPT-1
It was introduced in 2018. It uses 117 million parameters for training purposes. It uses a book corpus dataset. It has limitations on generating long-range text. It isn't able to generate a paragraph.
2. GPT-2
It was released by OpenAI in 2019. It is a much larger model with up to 1.5 billion parameters for training has a significant improvement in generating contextually relevant text. It highlights the model’s ability to perform multiple NLP tasks.
3. GPT-3
Released in 2020, it uses 117 billion parameters. It was one of the largest transformer models to generate context-aware text (text is dependent on the text).
4. GPT-3.5
It is an upgraded version of GPT-3, which has higher efficiency and accuracy. It is faster and more affordable to execute compared to GPT-4. GPT-3.5 is used in apps such as ChatGPT (GPT- 3.5 Turbo).
5. GPT-4, GPT-4o
GPT-4 is released in 2023, and GPT-4o is released in 2024. It is more efficient and powerful compared to older ones. It is improved in images and text. GPT-4o is easier and faster than regular GPT-4.

How GPT Generates Text
When you submit a prompt, GPT uses the following procedure:
(a) Tokenization
In the following example text is split into tokens.
Example: - This college name is PCCOE? - > [“This”, “college”, “name”, “is”, “PCCOE” “?”]
(b) Context Understanding
Uses self-attention to examine word relationship. Takes structure of sentence meaning, and context.
(c) Probability Prediction
Assigns probabilities to likely next words from learned patterns. Example:
The sky is → Most likely next words: “blue” (80%), “cloudy” (15%), “falling” (5%).
(d) Text Generation
The model chooses the most likely word (or sometimes a bit less likely one for variation). Does it again until the response is finished.
Key Features of GPT
(a) Transformer Architecture
(b) Attention Mechanism
(c) Temperature & Sampling
BERT
(Bidirectional Encoder Representation Transformer)
Introduction to BERT
BERT stands for Bidirectional Encoder Representation Transformer. The year 2018 appropriately saw the launch of BERT by Google, which happens to be a very deep and robust model. This is step for Natural Language Processing because it allows predicting parts of a sentence from any part of the text. Hitherto, all other models could not handle operations from both ends. That explains why BERT performs very well when applied to tasks like question-answering tasks, sentiment analysis, or text classification.

How BERT Works:
The basic architecture of BERT is based on that of the Transformers. In this case, however, it doesn't rely on sequential mechanisms rather, it tries to look at the different words in a sentence simultaneously. This is done by calculating the attention of one word to another inside a sentence. Whereas until now models were looking at sequences, this time they can look at dependencies with the help of the self-attention mechanism. The main features of BERT can be summarized as:
Bidirectional Contextual: In the past Language models have been mostly unidirectional and not bidirectional inputs. BERT reads a sentence but captures context emanating from all directions simultaneously.
Masked Language Model (MLM): the portion of the word of the input sentence is masked and model is trained and predict the original value of the masked word based of context of surrounding.
Next Sentence Prediction (NSP): BERT will be trained to predict whether one sentence follows another in a given context to be able to develop relations between the sentences.
The Architecture of BERT

Fig. 2 Architecture of BERT
The architecture of BERT consists of several layers of Transformers (usually 12 or 24), each layer having:
Multi-Head Attention: The model is enabled to attend different parts at the same time for the input.
Feedforward Layers: Features represented are transformed there extracted.
Normalization and Dropout Layers: In this layer it avoids Overfitting and gives the Stabilize Training.
Code Snippet of BERT

This code snippet shows how a pre-trained BERT model is applied for classification of sequence using transformers library provided by Hugging Face and PyTorch. The BERT model and the BERT tokenizer are first initialized from the 'BERT-base-uncased' checkpoint, a model of BERT that has no distinction between capital and lower letters. The input sentence is "BERT is a strong NLP model," this is then BERT tokenizer will be tokenized, where in it is transformed into a PyTorch tensor with padding and truncation added as necessary. The code then performs inference with torch.no_grad(), which suppresses the computation of gradients to make it more efficient and memory-friendly, making it appropriate for use in inference. Tokenized input is then fed to the BERT model, and it generates logits—inactivated scores prior to any activation function such as SoftMax. Lastly, the logits are printed, which are the model's raw classification results. As 'BERT-base-uncased' is not fine-tuned for classification by default, a suitable model like 'text attack/bert-base-uncased-SST-2' (for sentiment analysis) should be employed for valid results. Inform me if you want changes for a particular task!
T5
(Text to Text Transfer-Transformer)
Introduction of the T5 model
Google Research brought the T5 model in 2019, and it gives a transformer-based structure that is capable of applying to numerous NLP tasks in a text-to-text framework. T5 doesn't generate numbers or labels; rather, each task needs to be translated into a text generation problem. The encoder-decoder structure consists of an encoder that conditions the input text and a decoder that generates the output text. Pretraining on C4 is executed with a masked span corruption task similar to that of masked language modeling in BERT. T5 can be used for specific applications like text translation, text summarization, text classification, or open-domain question answering. The model is therefore extremely reusable for a wide variety of applications.

Architecture of T5 model
T5 is based on the Transformer architecture introduced by Vaswani et al. in 2017. It comprises:
• Encoder-Decoder Structure: in this structure the encoder takes input data as a text and converts
it into a numerical representation, which is consumed by the decoder to produce output text.
• Self-Attention Mechanism: The model focuses on important words in the input to improve understanding.
• Feedforward Layers: To supplement learning, and to have intricate representations of the text.

Fig.3 Architecture of the T5 model
T5 follows a bidirectional encoding process which basically means the model uses input text to understand both the context provided before and after, and therefore it is better at context
Variants of T5
T5-instances scaled from small to 11B to make a gradient between performance and computational requirements:
Model Name and Number of Parameters:
Model Name | Number of Parameters |
T5-Small | 60 million |
T5-Base | 220 million |
T5-Large | 770 million |
T5-3B | 3 billion |
T5-11B | 11 billion |
Code snippet of T5 model

This Python code uses the T5 model for text summarization by leveraging the transformers
library from Hugging Face. It first loads the t5-small pre-trained model and its tokenizer, which converts input text into numerical format for processing. The input text starts with "Summarize:" to instruct the model on the task. The tokenizer encodes this text into input IDs, which are then passed to the model for generating a summary. The output which is the sequence of tokenized text is decoded into human-readable form and printed. This method enables the T5 model to generate short summaries effectively from longer text inputs.
GPT vs. BERT vs. T5
Feature | GPT (Generative Pre-trained Transformer) | BERT (Bidirectional Encoder Representations from Transformers) | T5 (Text-to-Text Transfer Transformer) |
Developer | OpenAI | Google AI | Google AI |
Architecture | Transformer (It Consist Decoder only) | Transformer (It Consist Encoder only) | Transformer (It Consist of both Encoder and Decoder) |
Pre-training Objective | Predicts next word | Predicts missing words | All tasks are performed as text generation |
Orientation | It is a Unidirectional | It is a Bidirectional | It Perform Sequence- to-Sequence |
Main Use Cases | Generation of text , chatbots, Generation of code | Question and Answering, Sentence embedding, sentiment analysis | Classification, Text summarization, translation, Q&A |
Strengths | It can performs | Very good | Versatile, it can tackle several NLP tasks in a single model. Performs well in structured text transformations. |
| coherent text | understanding of | |
| generation | sentence relationships. | |
|
| and handling missing words. | |
Weaknesses | Doesn’t deeply understand relevance of text, can generate delusion. | It is not able to generate text and handle long sequences well | Requires large datasets for training, computationally expensive |
Examples of Variants | GPT-2, GPT-3, GPT-4, GPT-4o | BERT, RoBERTa, ALBERT, DistilBERT | T5, mT5 (Multilingual T5), FLAN-T5 |
Best for | Content generation and chatbots | Understanding and analyzing text | General NLP tasks with text transformation |
You can also refer this video to learn Comparing Large Language Models: GPT vs. BERT vs. T5
Conclusion
GPT, BERT, and T5 are powerful large language models, but each of them has different purposes. GPT is best for generating human-like text and conversations. BERT is great for understanding and analyzing text, like for question answering and classifying sentences. As T5 can understand and generate text, which makes it useful for tasks like text translation, text summarization, and question-answering so it is most flexible. If you want text-generation, use GPT. If you want understanding of text, use BERT. If you want a mix of both, T5 is the best choice.


Excellent work and very informative blog
Valid and Informative 💯
Very Informative..!!
"Nice breakdown of concepts! 💡"
Superb